Can VLMs Understand Without Generating?
Mohamed Rayan Barhdadi
What I cannot create, I do not understand.
-- Richard Feynman
VLMs are built for visual understanding. They take images or video frames as input and output text. They do not generate images or videos.
Most VLMs have three main components:
- A vision encoder, often CLIP-style and trained with contrastive matching.
- A projector that translates the output of the encoder above to the input of the decoder below.
- A decoder that only outputs language.
The quote from Richard Feynman raises a question. Does a model understand what it cannot generate? More specifically, does the lack of visual generation limit what VLMs can understand? Can generation and understanding live in the same latent space?
TLDR: Vision language models have structural limits that affect visual understanding. We explore whether the strengths of generative models can transfer to VLMs and help close that gap.
The bag-of-words problem
Let's start with a simple example. CLIP-style encoders are trained via contrastive learning where the model learns to map an image and its corresponding caption to the same vector, i.e. have the same representation. The objective function is the similarity score between pairs of text and image embeddings.
One problem with this approach is that the model can succeed without full visual understanding. Such models learn to match keywords in the caption by relying on the main object, often ignoring the rest of the scene (Fig. 1).

Researchers have built tests to show that word matching is not enough. In Winoground [CVPR 2022], a model must distinguish captions with the same words but different relations:
- "Some plants surrounding a lightbulb"
- "a lightbulb surrounding some plants."
For humans, these tasks are trivial. However, CLIP-style models often fail, and some scores fall below random chance. Follow-up work, including When and Why LM behaves like Bag of Words [ICLR 2023] and SugarCrepe [NeurIPS 2023], found a similar pattern.
The failure is binding. The model detects what's in the image, but it does not reliably bind objects, attributes, and relations together.
The encoder is not alone
One might argue that this problem disappears in VLMs because they do not use the encoder alone. They add a decoder on top.
But the decoder does not fix what the encoder fails to preserve. Eyes Wide Shut [CVPR 2024] tested VLMs on visual question answering and found that they miss obvious visual differences, e.g. dog facing left vs right.
The issue starts in the visual representation. Encoder embeddings often bind strongly to objects, but weakly to position, attributes, and relations. If those details are missing from the encoder output, the decoder has little to reason over.
The problem is structural. We need to separate two cases:
- In LLaVA-style pipelines, the visual encoder is frozen. Only the projector is trained. The language model can only reason over what the encoder preserves.
- Newer models often unfreeze the encoder during pre-training. For example, Qwen3-VL trains the vision stack end to end after a short alignment stage. But these models still start from contrastive checkpoints, and similar failures appear even in frontier VLMs.
This leads to the central question: is the visual encoder a ceiling?
Does image generation fix this understanding problem?
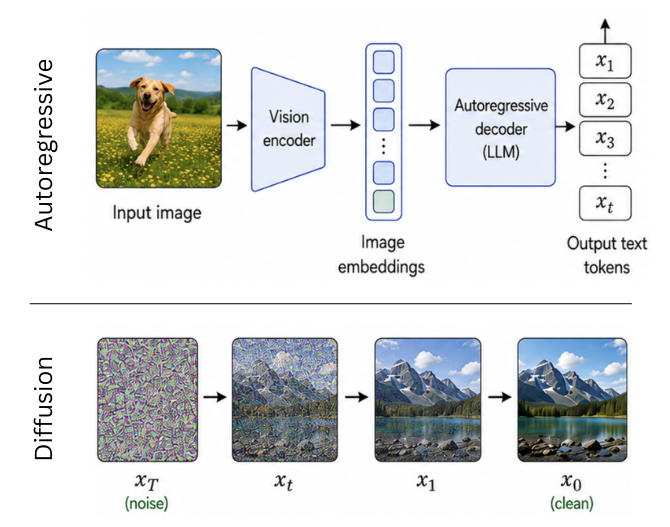
Generative models work differently. For example, Stable Diffusion learns to generate images from captions through repeated denoising (Fig. 2).
Though they are designed for generation, they can be repurposed for understanding.
You can modify a diffusion generative model and use it as a classifier with one clever trick. Take an image and a set of captions, add noise to the image, then ask the diffusion model to denoise it under each candidate caption. The caption that reconstructs the image best gets the lowest error and wins. In this setup, the generator becomes a zero-shot classifier, as shown in Your Diffusion Model is a Zero-Shot Classifier [ICCV 2023].
This approach beats CLIP on the binding tests we talked about earlier. And it does, because the objective of the model initially is to reconstruct the image from the caption, every word will land somewhere in the output pixels. A dog to the left of a rock must become a dog to the left of a rock. Which enforces the binding in a generative loss.
But this comes with a major limitation: inference is computationally expensive. Diffusion-based classification requires one reconstruction pass per candidate caption. That is, to classify one image amongst one million captions, we must score one million candidates. In contrast, models such as CLIP project images and captions into a shared embedding space, meaning an image can be embedded once and finding top 100 captions out of a million is a simple nearest neighbor search, provided the captions are already embedded.
So diffusion models can be strong zero-shot classifiers, especially when binding matters. But they are not practical replacements for CLIP-style retrieval at large scale.
Do unified models transfer between the two?
The next question is whether one model can learn both understanding and generation in a way that makes each ability stronger.
Show-o2 [arXiv 2025] is an example of this direction: it puts multimodal understanding and visual generation inside one transformer, using a shared token space and separate objectives for text prediction and image generation. What we would need is a controlled ablation: same model, data, and compute; with and without the generation head; then evaluate the model's understanding for binding.
Existing unified models show that the two abilities can coexist, but they do not fully answer whether generation causally improves understanding.
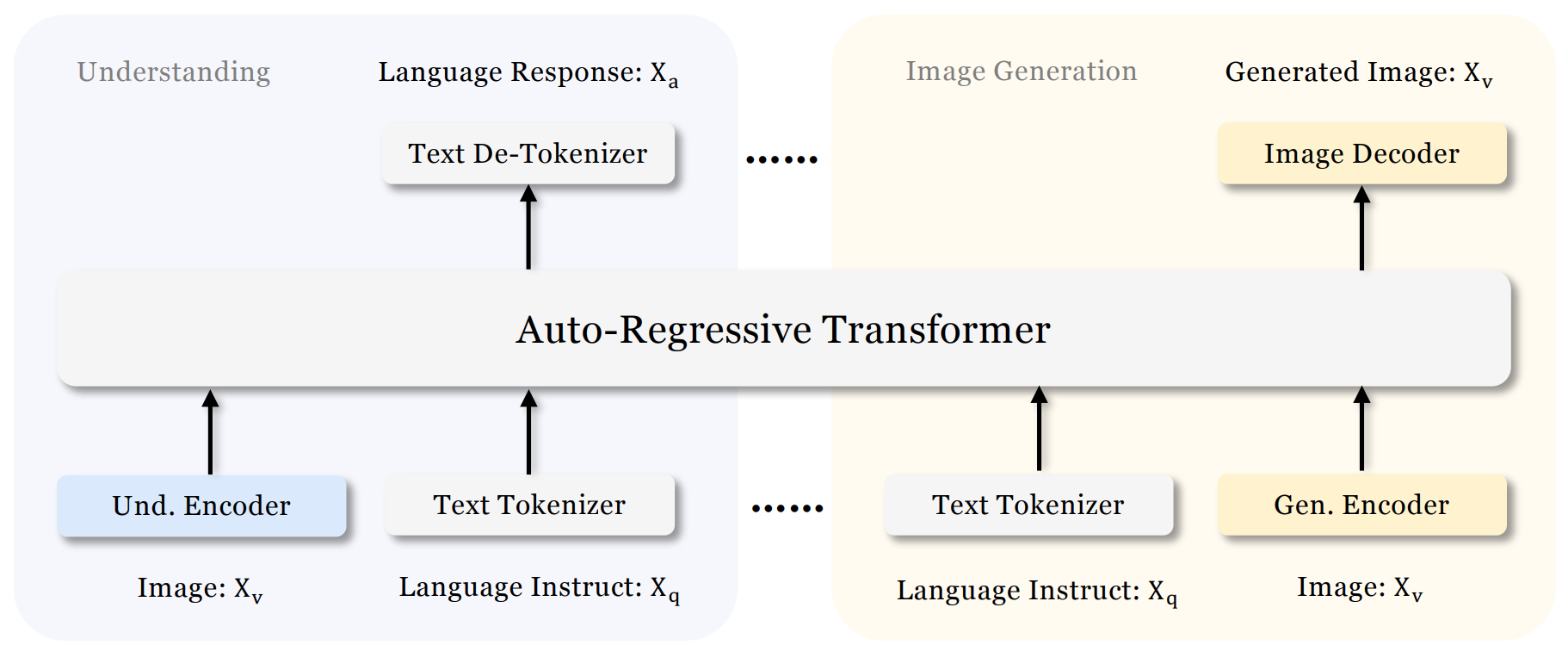
Janus [CVPR 2025] differs from Show-o by separating two design choices: (1) should understanding and generation share the same visual encoder? (2) can they share the same transformer? It keeps one autoregressive transformer, but separates the visual pathways: a SigLIP-style encoder for understanding and a VQ tokenizer for generation (Fig. 3).
The motivation is that understanding needs semantic features, while generation needs fine spatial and texture information. In their ablations, forcing one visual encoder to serve both tasks creates a trade-off, especially hurting understanding. So one network can host both abilities, but at the perceptual level, understanding and generation seem to prefer different visual representations.
Finally, JEPA changes the question and proposes a new approach
JEPA [arXiv 2023] offers a third path. It does not choose between visual understanding and generation. Instead, it argues that pixel-level prediction, i.e. generation, is the wrong target for learning semantic representation.
The reason is simple. A generation model reduces its loss by repainting every blade of grass. But understanding may only require the model to know that grass is present. Predicting pixels can therefore spend "encoding" capacity on details that are not semantically useful.
JEPA changes the objective. It keeps part of the input visible, the "unmasked" region, and hides the rest, the "masked" region. The unmasked region gives the model context. The masked region becomes the target. The model predicts the target's latent representation from the context, rather than generating the target pixels directly.
I-JEPA [arXiv 2023] and V-JEPA [arXiv 2024] showed that this approach can compete with image and video generation methods respectively while using less pretraining compute. The representations produced by the models transfer to motion and appearance tasks, such as action recognition, using only a lightweight classifier and no backbone fine-tuning.
V-JEPA 2 [arXiv 2025] extends this line from representation learning to prediction and planning. The paper introduces V-JEPA 2-AC, an action-conditioned variant that is post-trained on robot trajectories and used as a latent world model for choosing robot actions.
JEPA models have not, to my knowledge, been tested on the binding benchmarks discussed earlier. So it would be interesting to see how they perform.
So, can generation models help VLMs understand?
VLM understanding may have a ceiling set by the visual encoder. The model can only reason over the information that the encoder preserves.
Contrastive training does not reliably preserve binding because the loss does not require it. Generation is one way to enforce binding: the caption must explain the image. But generation is too expensive for large-scale understanding. Latent prediction, as in JEPA, offers another path by moving prediction into representation space.
We propose an experiment: one model, same data, same compute, with and without a generative head, scored on binding.
The question is still open. Diffusion classifiers show that binding can be recovered when the objective demands it, but they are too slow for deployment. The practical answer may be to move that cost into training: better encoders, mixed features, or latent-predictive pretraining.
If you enjoyed this blog, you will certainly enjoy working with us. Reach out to founders@overshoot.ai