How a small fix improves Gemma 4's performance by 10x on vision tasks
Zakaria El Hjouji
In this blog post, we share a simple fix that improves Gemma 4's performance on vision tasks by 10× while preserving bit identity (i.e., no change in predictions).
Most inference engines (e.g., vLLM, SGLang) are designed primarily for text workloads and optimized for high throughput. However, when it comes to real-time inference on live video, the default deployments don't perform well.
Setup
For this blog post, we use vLLM as our inference framework. We deploy the model as follows:
vllm serve google/gemma-4-E4B-it \
--no-enable-prefix-caching \
--mm-processor-cache-gb 0 \
--async-scheduling \
--limit-mm-per-prompt '{"audio": 0}'
Note that we turn off prefix caching and multimodal processor cache so identical requests don't hit the cache and distort our measurements during benchmarking. We also turn off audio, as we don't support audio input right now.
How do we benchmark?
To benchmark model performance, we use guidellm to run a sweep of requests at varying rates, from 1 request per second up to 20 requests per second, at a constant rate. For each rate, we measure tail TTFT and median ITL. We found these metrics to be the best for benchmarking real-time workloads.
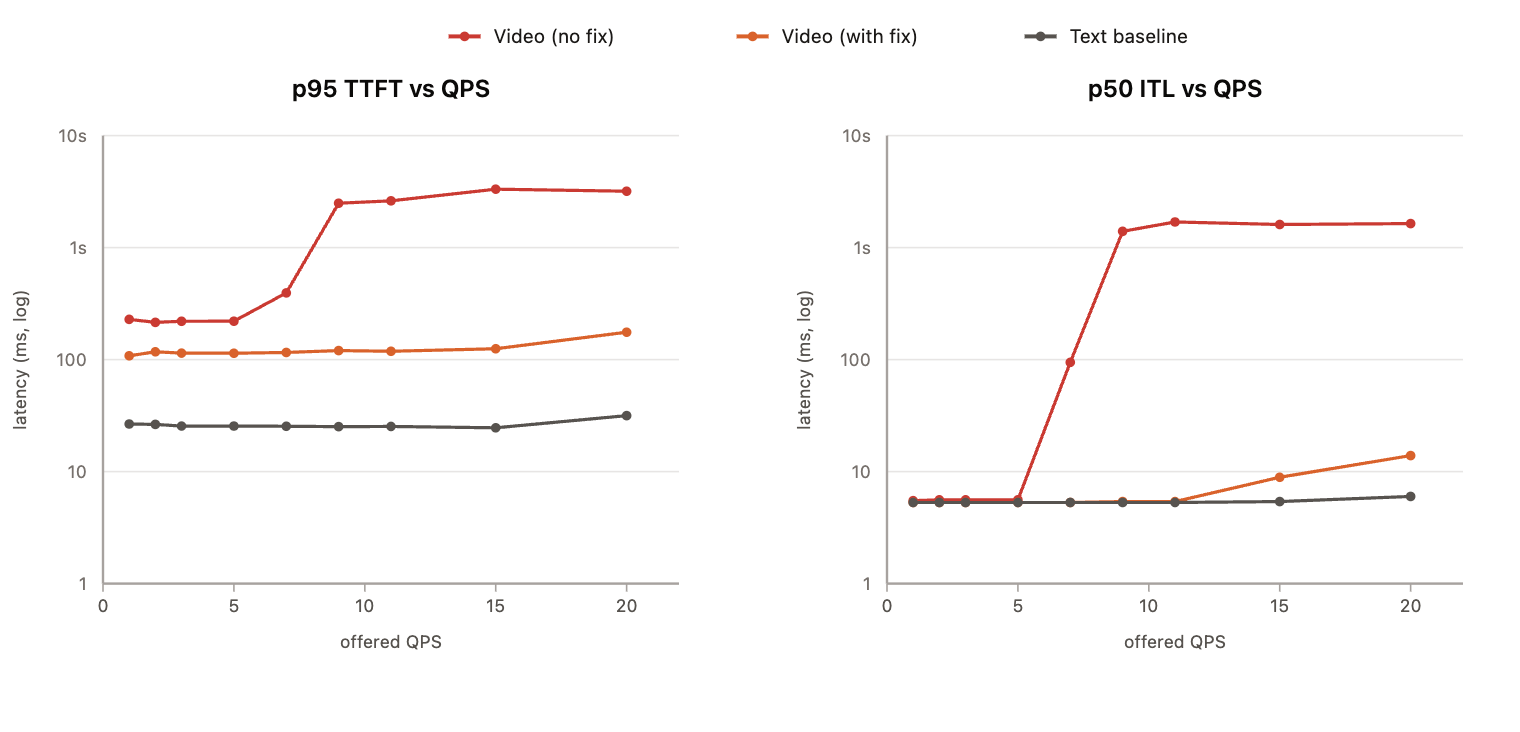
The graph below shows the latency-throughput profile of Gemma 4 on two types of requests with similar input and output sizes.
- Text-only requests: these requests contain ~500 text input tokens and 10 output tokens
- Video requests: these requests contain 6 frames @ 480p in the input. This translates to roughly ~500 tokens (comparable with the text-only requests).
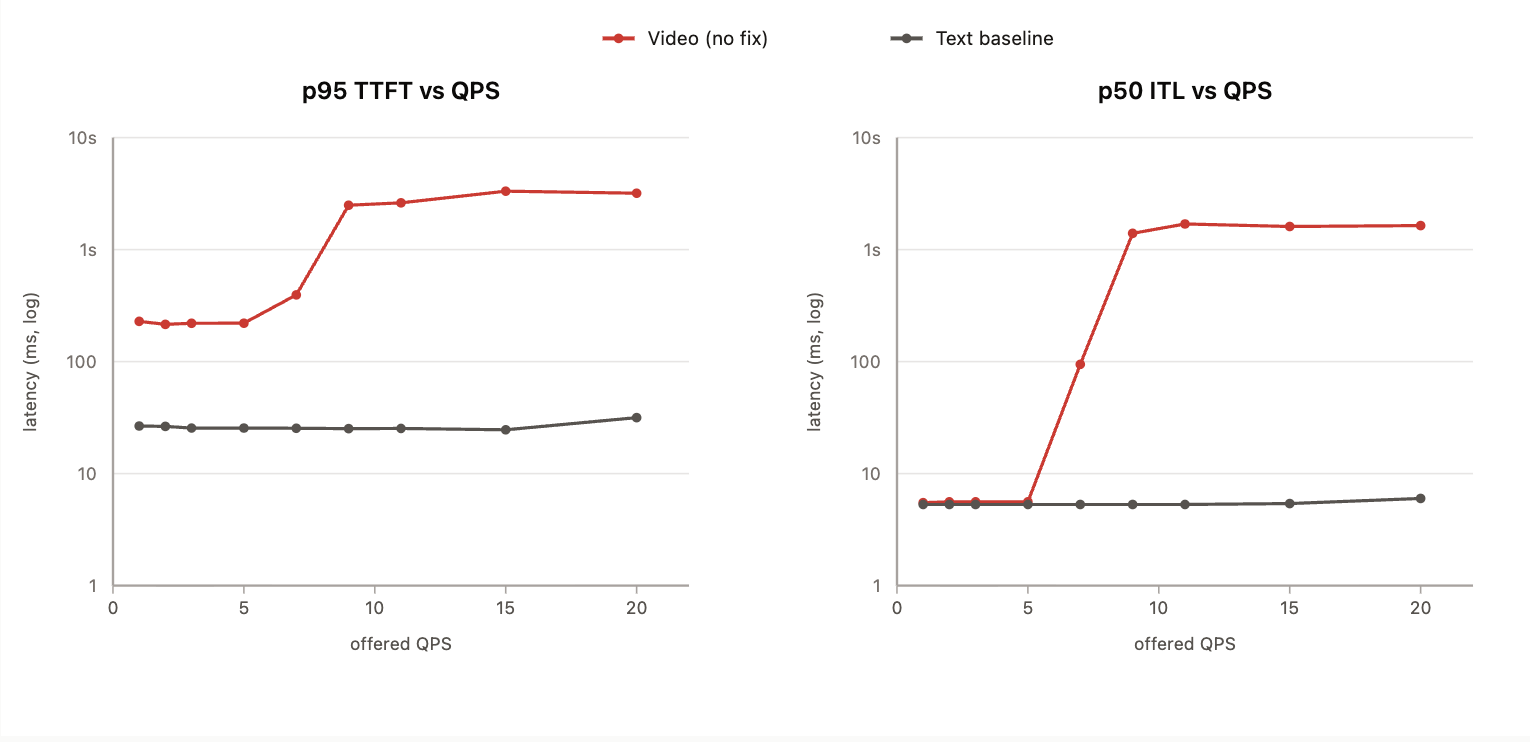
Note that the y-axis for both graphs is log-scaled! In other words, the differences are a lot larger than they seem.
For a single request, we see that p95 TTFT for a video request is 10× (25 ms vs. 225 ms) that of a text-only request with the same input size (500 input tokens). This tells us that the vision encoder adds roughly 200 ms. As QPS grows, tail latency grows slowly and then shoots up around 5 QPS to 2+ seconds, while the text baseline remains around 25 ms (100×).
We see a similar pattern in ITL. Median ITL is similar between text and video requests until we hit 5 QPS, after which it explodes to ~2 s. Meanwhile, the text baseline stays consistent around ~5 ms.
Our goal in this blog is two-fold:
- reduce the discrepancy between text and video requests for a single request
- maximize the QPS while keeping the p95 total request latency ≤ 300ms
Continuous Batching
The fix lives inside of the vision encoder. But before digging in there, let's understand the scheduling loop of vLLM.
For the sake of simplicity, let's assume we have only one request. This request (text or video) produces 10 output tokens. It does that over 10 iterations inside vLLM. One output token at a time. The first iteration is what inference engineers like to call a prefill. The other nine iterations are called "decode". Why do they have different names? The reason they have different names is because they have different compute and memory profiles and therefore they are "treated" differently. Prefill is compute-heavy. It processes the full input prompt, builds the KV cache and emits the first token. Decode is compute-light. It processes the last token by pulling the entire KV cache (hence memory bandwidth) and emits one token.
If we have multiple concurrent inference requests, some of them might be in the prefill stage (new requests) and others in the decode stage. In each iteration, vLLM packs the in-flight prefills and decodes together and runs them in a single forward pass. We call this continuous batching.
Prefill with image / video >>> prefill with text only
Now, here's the catch. If any of the prefills in a single iteration contains an image or video in the input, the whole iteration will have to wait for the image and video to go through the vision encoder first. Then, once we get the vision tokens, the forward pass will occur.
This implies that if the vision encoder is not well optimized for big batches, it will slow every other request. And that's exactly what happens. We can infer this overhead from the graph above to be ~200 ms (TTFT video at QPS = 1 minus TTFT text-only at QPS = 1). This means that if a prefill happens to belong to an iteration, a single decode will take 200 ms instead of 5 ms.
And the crazy thing is that this scales linearly with the number of prefills with images/videos in an iteration. Yes, linearly. Let's look at the following examples of iterations:
- 5 decodes: 5 ms
- 1 prefill text-only and 4 decodes: 25 ms
- 1 prefill video-only and 4 decodes: 225 ms
- 2 prefills video-only and 4 decodes: 550 ms
- 8 prefills video-only and 4 decodes: 1700 ms
What happened to GPUs being designed for embarrassingly parallel workloads?
Not that parallel after all
When a batch of prefills reaches the vision encoder, you would expect it to process them in parallel. It does not. It processes them serially, one at a time. Not one video at a time, literally one frame at a time.
The code snippet below is from the video encoder path. The outer loop walks the videos in the batch of prefills that contain image / video. The inner loop walks the frames in each video. Every frame gets its own blocking forward pass through the vision tower.
for pv_chunk, pp_chunk in zip(pv_per_video, pp_per_video):
frame_embs = []
for i in range(pv_chunk.shape[0]):
pv = pv_chunk[i].unsqueeze(0)
pp = pp_chunk[i].unsqueeze(0)
max_patches = pv.shape[1]
output_length = max_patches // pooling_k2
vt_output = vt(pv, pp, output_length=output_length)
frame_emb = self.embed_vision(
inputs_embeds=vt_output.last_hidden_state.unsqueeze(0).to(target_dtype)
).squeeze(0)
frame_embs.append(frame_emb)
per_video_embeddings.append(torch.cat(frame_embs, dim=0))
Batching them I guess
The simplest version stacks every frame in the batch and runs the vision tower once. Each frame is independent of the others, so the math is the same whether they are processed serially or together.
Yes, not so fast though. This loop exists for a reason. A batch of prefills might have images and videos of different resolutions, aspect ratios and token budgets. As a result, they need to be padded accordingly, and also keep track the token budget for each separate request.
After implementing the above, we noticed a slight drift at the bit level; that is, the outputs of the vision encoder differed slightly (~1.7%). Upon further investigation, we're happy to announce that we couldn't figure out exactly why. We found that the drift happened at the pooling layer inside the vision encoder, but it was unclear why. So we resorted to running the pooler sequentially while batching the other parts of the vision encoder.
Results:
As expected, batching improves performance significantly in many ways:
- Reduces the discrepancy in TTFT between text and video for a single request from 200 ms to 80 ms
- TTFT stays flat around 120 ms even at 20 QPS instead of 3 s (20× improvement)
- ITL stays flat at 5 ms up to 10 QPS instead of 2 s (400× improvement)